Videlicet
What is Videlicet™?
Videlicet™ is an Artifical Intelligence (AI)-enabled Information System. It can execute and measure the accuracy of one to many Prompts using one to many AI Large Language Models (LLMs), resulting in an archive that is searchable via patent-pending semantic search capabilities.
Videlicet is a historical archive, transcription, and search system that enhances users’ ability to find, read, and utilize primary sources. The project focuses on AI-enabled transcription and searching capabilites. Videlicet makes history more accessible, searchable, and encourages connections between the documents. Currently, Videlicet makes over 50,000 documents searchable.
Videlicet Overview
Why Videlicet is unique:
Word searchable archive
Videlicet’s AI enabled Semantic Search (US Patent pending) extracts word meaning, rather than character matching, to create connections, trace trends, and identify relationships between documents. Videlicet is capable of conducting both semantic and keyword/full-text searching and caters to a diverse array of historical inquiries.
Better accuracy
Videlicet uses AI technology to transcribe handwritten, degraded, or irregularly formatted historical documents that are incompatible with modern transcription technology. Tools like Optical Character Recognition (OCR) struggle with Early Modern documents and do not always provide accurate transcriptions. AI LLMs are smart and adaptable, providing transcriptions that more accurately reflect the documents.
Extract any text
Videlicet has the ability to extract any text from any publication. For example, the text can be handwritten court records from the 1700s, Spanish shiplogs from the 1800s, and newpaper archives.
Extract whole sections
Videlicet has the ability to identify and extract sections of data from a page or series of pages. For example, if you ask Videlicet to find all the poems in the Maryland Gazette for the year 1799, it will return just the pages with poems from the publication and year.
Transcription accuracy
Videlicet employs a novel quality measurement evaulation system to ensure transcription and searching accuracy. AI can hallucinate. The Videlicet evaulation system returns level of accuracy between a human transcription and an AI transcription using Levenshtein distance.
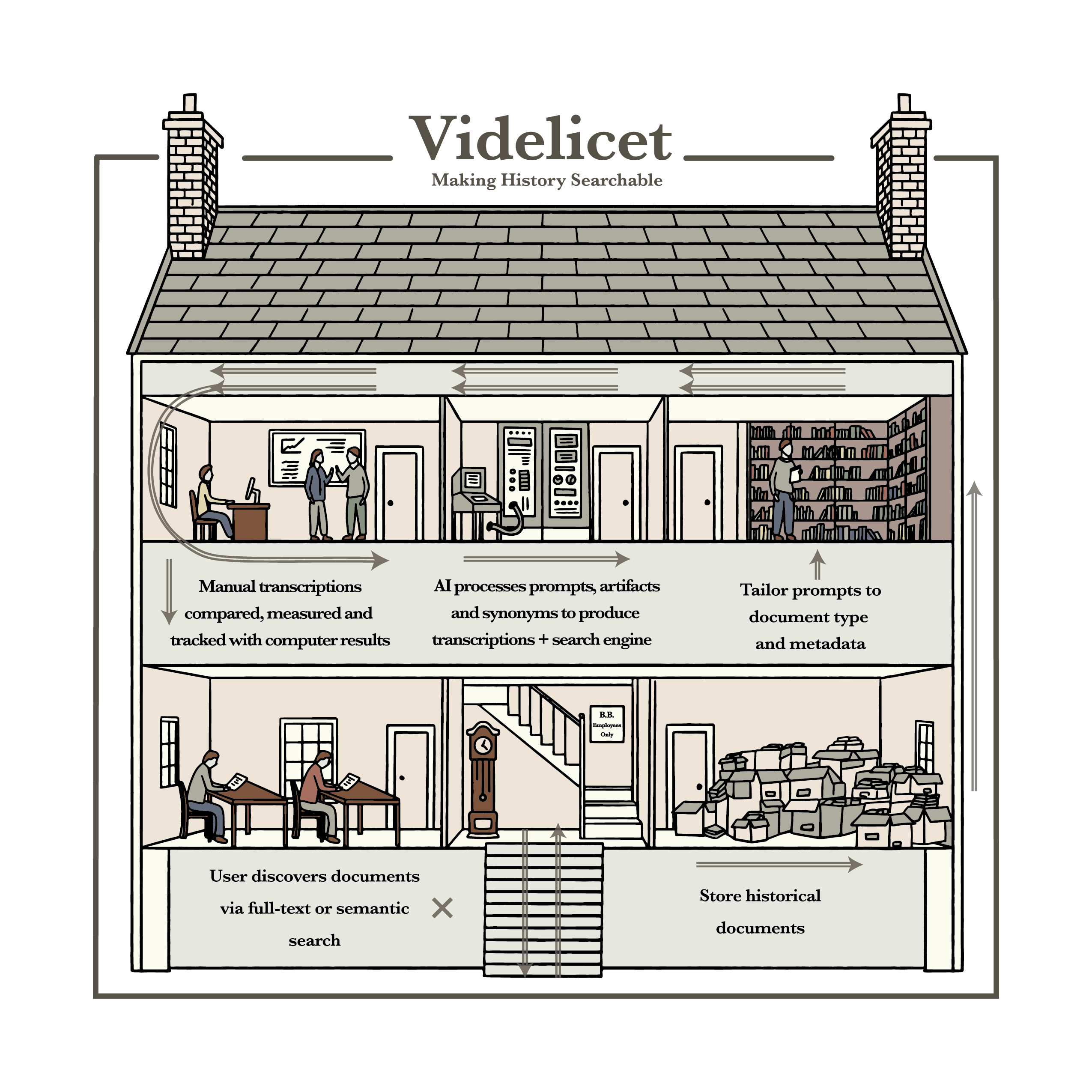
How does Videlicet work?
- Documents are collected, found, and scanned into the Videlicet archive.
- Prompt engineers develop one or more prompts per dataset to instruct the LLM in transcription practices.
- A subset of the documents are manually transcribed by people.
- Evaluations are performed to compare the computer-transcribed and person-transcribed documents. The results are calculated using the Levenshtein distance.
- Researchers iterate this process until the Levenshtein score shows accurate processing of the document.
- The prompt is run against the full subset of documents. The results are stored in the database for user searches and research.
- Documents are now available to search.
Semantic versus keyword search:
Overview
Semantic search: searching based in word meaning. Prioritizes synonyms and identifying relationships between words or phrases.
Keyword/full-text search: searching based on character matching. Identifies instances in the corpus that have a direct character match with the search term.
Example and uses for semantic search
A researcher is looking for all instances of an enslaved man named Parris, who ran away multiple times. The researcher wants to look at all the newspapers in the Videlicet database to determine how many times this man ran away, and how far he went. Parris’s name was spelled two different ways in the runaway ads: “Parris” or “Paris.”
Keyword searching will find all instances of the word “Parris,” which likely refers to the enslaved man. However, it will also pull every instance of “Paris,” resulting in many false hits for the French city. This obscures the runaway man and prevents meaningful connections to be made across datasets.
Semantic search will understand a search for “enslaved man named Paris,” and only return matching sections. The system understands that the search is not for the city, but a specific person.